
Metadata Resources
The resources below provide an introduction to metadata and different metadata annotation levels, and include explanations of why researchers should annotate their studies at each level.
Metadata in the HEAL Data Ecosystem
The NIH defines metadata as "Data that provide additional information intended to make scientific data interpretable and reusable (e.g., date, independent sample and variable construction and description, methodology, data provenance, data transformations, any intermediate or descriptive observational variables)."
The HEAL Data Ecosystem is powered by metadata; information describing data. By sharing study metadata, investigators make their data more Findable, Accessible, Interoperable, and Reusable (FAIR). SLMD, VLMD, and CDE information supports the HEAL Data Platform and HEAL Semantic Search, promoting research discovery. For a brief overview on the importance of data sharing in the HEAL Data Ecosystem, see the Fresh FAIR Webinar Recap: Advancing Open Science with the HEAL Data Ecosystem.
The HEAL Data Ecosystem incorporates three types of research study metadata:
- Study-level metadata (SLMD): describes a HEAL-funded study.
- Variable-level metadata (VLMD): describes the variables collected by a study.
- Common data elements (CDEs) usage information: schemas that contain standardized variable descriptions, collection protocols, question text, units, and permissible values. Using the same CDEs can enable data collected by different studies to be harmonized. Studies are encouraged (and, in some cases, required) to use HEAL CDEs.
Study-level Metadata
Overview
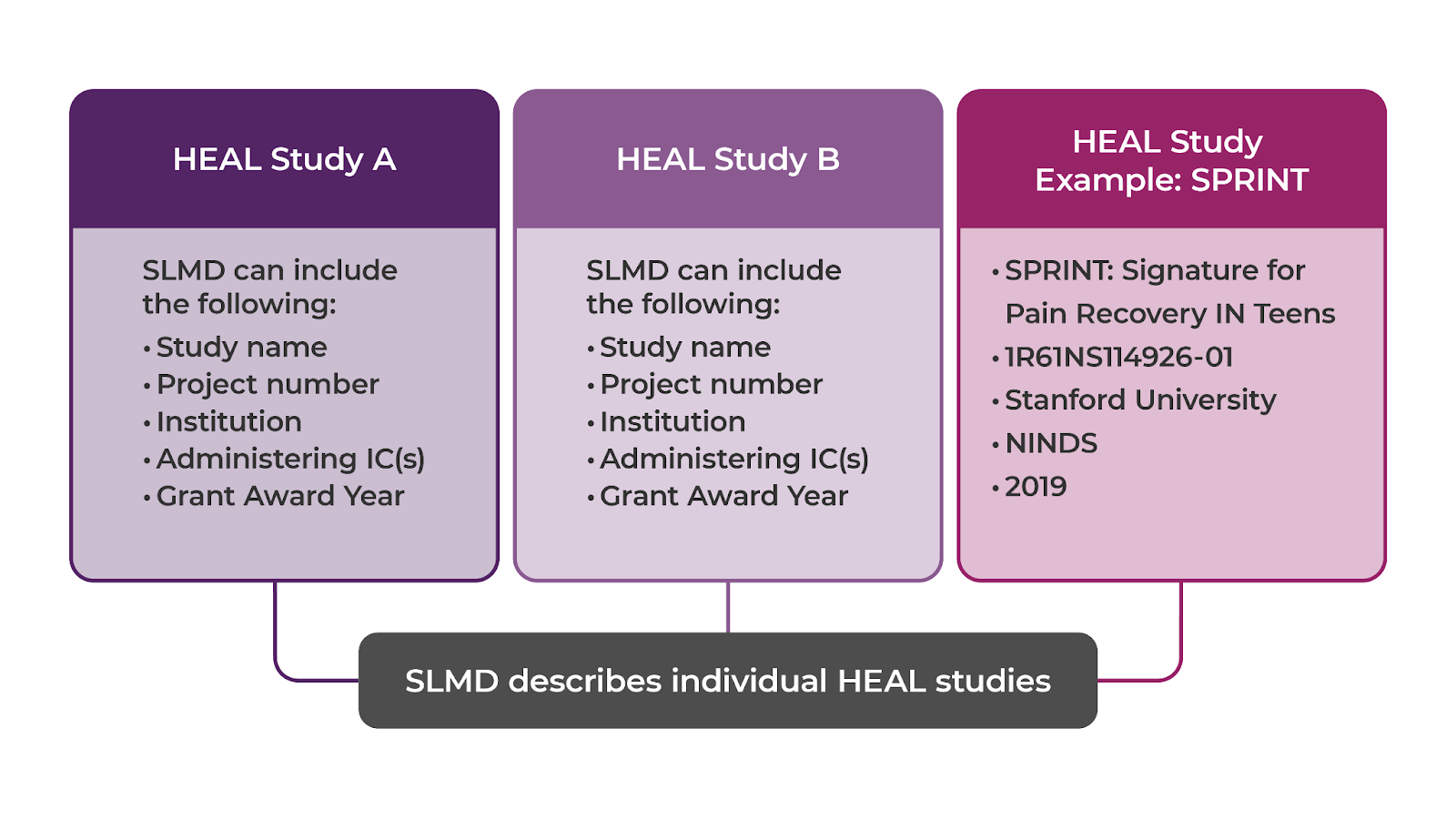
For the NIH HEAL Initiative®, SLMD is the highest level of metadata and includes information like a study's name, description, unique identifier, and investigators. This metadata enables discovery of datasets generated by HEAL funded studies on the HEAL Platform. Although the actual data files are stored in data repositories, users can search for and find HEAL study datasets on the HEAL Platform.
The NIH requires most HEAL Investigators to provide SLMD via a CEDAR form. Complete this form within one year of receiving your award. Additionally, update the SLMD as needed at the study’s completion and/or when releasing study data.
How to submit SLMD via the CEDAR Form
To submit SLMD, register your study on the HEAL Data Platform. HEAL Platform registration is a simple, three step process:
- Request access to register your study.
- Create a CEDAR account. It is best practice to use the same email address as in in Step 1.
- Register your study on the HEAL Data Platform.
After registering on the HEAL Platform, a CEDAR SLMD form for your study is automatically created.
To fill out and submit your CEDAR SLMD form, follow the documentation here or follow along with the tutorial playlist. To update SLMD after submitting the CEDAR SLMD form, contact the HEAL Platform.
To request support, please contact the HEAL Platform team.
For further registration information, please see the HEAL Fresh FAIR webinar on Platform registration and the Platform registration tutorial videos.
Resources
- Checklist for HEAL-compliant Data (see step "Complete Your Study-Level Metadata Form")
- Study-level metadata submission webinar recording
- CEDAR SLMD form tutorial
- CEDAR SLMD form documentation
- HEAL Study-Level Core Metadata v1.0.0 List of Fields - Describes all HEAL's SLMD CEDAR form fields. These metadata fields were carefully selected to empower HEAL data discoverability on the Platform.
- SLMD FAQs
Variable-level Metadata
Overview
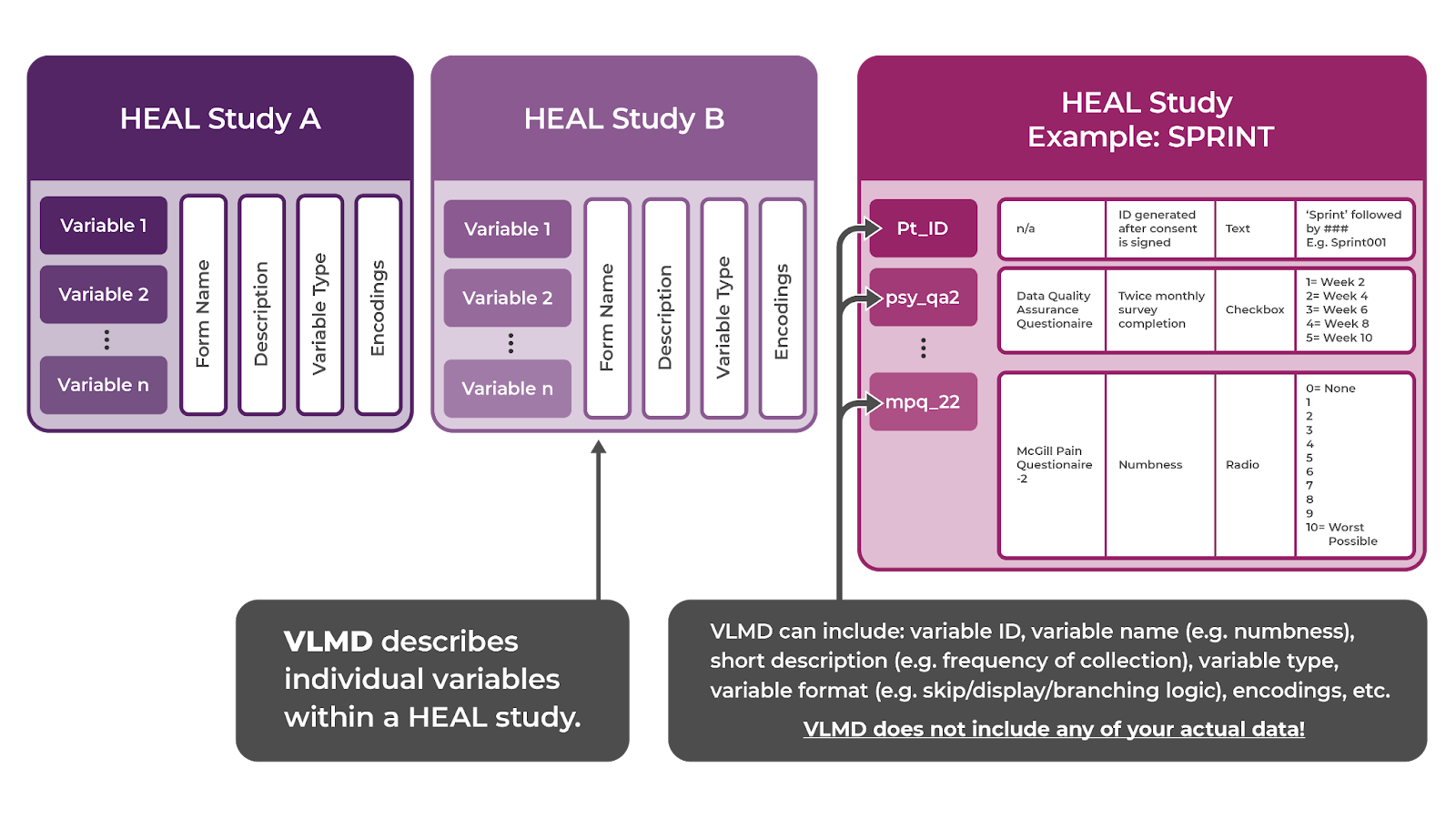
VLMD describes study data, providing information that facilitates data reuse. VLMD is most commonly stored in a data dictionary and includes variable names, descriptions, measurement information (question items, CDEs, CRFs, etc.), variable types (e.g., string, date, numeric), and permissible values. VLMD does not include any of your actual data.
VLMD significantly enhances research data discoverability and reusability. By providing detailed study variable descriptions, VLMD helps researchers identify datasets related to their research area for collaboration, harmonization, and/or data reuse.
HEAL Semantic Search and the HEAL Platform rely on VLMD to deliver search functionality to make data more Findable, Accessible, Interoperable, and Reusable (FAIR).
The HEAL Initiative requests or requires (depending on award terms) studies collecting tabular data to share their data dictionaries (VLMD), benefiting the researcher community and enabling better collaboration and knowledge generation. Submit VLMD after your data dictionary is finalized and no later than publication or final data submission.
VLMD Submission Process
A data dictionary extends beyond VLMD by including broader metadata structures, variable relationships, and collection protocols.
HEAL studies should submit VLMD as a data dictionary through HEAL Platform's VLMD submission system or by emailing it to the HEAL Stewards. If your VLMD changes, please re-submit updated VLMD via either channel. VLMD may change if additional data are generated or derived or if variables are transformed, such as by changes in data processing code. VLMD is usually updated when data analysis is done and data will not be adjusted or changed.
Depending on your choice of repository, you may also submit the data dictionary to the repository when depositing data.
To request VLMD submission support, contact the HEAL Platform team. For other VLMD questions, contact the HEAL Stewards.
Resources
Common Data Elements
Overview

Common Data Elements (CDEs) are precisely defined and standardized measures, paired with allowable responses or acceptable data types, used systematically across different sites, studies, or clinical trials to ensure consistent data collection. CDEs may be grouped or bundled into questionnaires or CRFs for research or clinical purposes. By ensuring consistent data collection, CDEs act as a foundational template for data recording and collection and downstream data harmonization efforts.
It is important to distinguish between these concepts:
- Validated Questionnaires: These are specific, formally validated question sets measuring a particular concept of interest, and may also be referred to as CRFs. For example, the PHQ-9 (Patient Health Questionnaire-9) is a validated questionnaire with nine questions (CDEs) measuring depression severity. When using validated questionnaires, it is crucial to administer all questions exactly as specified to maintain instrument validity.
- Case Report Forms (CRFs): In broader usage, CRFs are more expansive than a single questionnaire and may include multiple questionnaires administered at the same time. While validated CRF questionnaires must remain intact for validity, individual CDEs from other CRFs can still retain their meaning, even if used separately in different parts of the data collection process.
- Custom Questionnaires: These are unvalidated question sets developed for specific studies. Some items on a custom questionnaire might resemble validated questionnaire CDEs but not strictly adhere to the validated CDE specification. Others might be original items authored by the study team.
Different organizations and programs, including the NIH and the HEAL Initiative, define their own CDEs. These are developed by subject matter experts who examine CDEs used by similar past studies, identify precise question text and measurement scales, and validate their CDEs by testing whether they accurately capture the variables of interest. The HEAL CDE team (heal_cde@hsc.utah.edu) or CDE experts at the NIH or your organization can assist with planning for CDE use during data collection. Some validated instruments may be subject to copyright or other licensing restrictions, and in such cases, a review copy might be available to aid in the decision to license them.
The HEAL Initiative's clinical pain research studies must collect a core group of CDEs to measure the most important pain domains. Depending on the research study's purposes, they may also use supplemental CDEs/CRFs. All HEAL studies collecting data from human participants should search for applicable CDEs in the HEAL CDE repository.
CDEs Submission Process
Studies using any CDEs, HEAL-approved or otherwise, must report which CDEs they use to the HEAL CDE team at heal_cde@hsc.utah.edu. For more information, please refer to the HEAL CDE program website or contact the HEAL CDE team at heal_cde@hsc.utah.edu.
Resources
Other Data Standards
Overview
In addition to SLMD, VLMD, and CDEs, other data standards may enhance data interoperability. There are many types of data standards, including data models, ontologies, and controlled vocabularies, which provide a common framework for encoding information. These standards are usually maintained by formal communities of practice. They enhance interoperability and harmonization between variables and datasets from one or more different studies, thereby facilitating more robust data integration and secondary analysis. Below are some examples of data standards widely used in medical research.
Variable Standards Finder: A New Tool to Support Your Study Planning
Use the HEAL Variable Standards Finder to identify variable standards appropriate for your study and data type. Based on your answers to eight questions, the Finder highlights data required standards that may apply to your data and recommended standards to increase data interoperability.
Data Standards Example
- PhenX Toolkit: While not a formal standard, the PhenX Toolkit is a freely available, online resource that provides standardized measurement protocols for biomedical research. By offering over 800+ rigorously vetted protocols, the PhenX Toolkit ensures that researchers collect data in a consistent and harmonized manner across studies. These protocols have been selected by domain experts to represent best practices and facilitate comparability of data across different research projects. By adopting PhenX protocols, researchers can reduce variability in data collection methods, enhance the interoperability of datasets, and enable integration of findings across studies, which is critical for advancing scientific discovery and maximizing the utility of shared data. The Toolkit is particularly useful for investigators working outside their primary expertise, providing a foundation for designing studies with high-quality, standardized data collection.
- LOINC (Logical Observation Identifiers Names and Codes): LOINC is a controlled vocabulary and document ontology used for health measurements, observations, and documents.
- SNOMED CT (Systematized Nomenclature of Medicine Clinical Terms): SNOMED CT is a controlled vocabulary and ontology containing comprehensive, multilingual healthcare terminology that provides a standardized way to represent clinical content, assisting to harmonize health data across various healthcare settings.
- CDISC (Clinical Data Interchange Standards Consortium): CDISC standards, such as SDTM (Study Data Tabulation Model) and ADaM (Analysis Data Model), provide a standardized approach for representing clinical and non-clinical research data, enabling consistent data collection, sharing, and analysis. CDISC maintains its own controlled vocabulary and allows use of other vocabularies, such as SNOMED CT and LOINC.
- MeSH (Medical Subject Headings): MeSH is a comprehensive controlled vocabulary used to index journal articles and books in the life sciences, facilitating a common language for research topics. The National Library of Medicine (NLM) maintains MeSH.
Repository Requirements
When preparing to deposit data into a repository, be aware that certain repositories may have specific metadata or data standard requirements. These may include adherence to particular metadata standards, controlled vocabularies, or data models to ensure the data's reusability and discoverability. For example, repositories like the National Institute of Mental Health’s (NIMH) Data Archive (NDA) and dbGaP require data to conform to specific formats for acceptance.
Repositories may require SLMD and/or VLMD submission as part of data deposition. They may require metadata in a format different from the format required by the HEAL Data Ecosystem. In most cases, HEAL SLMD and VLMD can simply be reformatted for repository submission.
To ensure compliance, always review the repository’s guidelines before depositing your data. This proactive step can save time and effort, ensuring your data is ready for submission and meets the standards for reuse by the broader research community.